The stats_t type and associated subroutines.
More...
Data Types | |
| type | stats_1d_t |
| Structure for online computation of 1D arrays of mean and variance. More... | |
| type | stats_2d_t |
| Structure for online computation of 2D arrays of mean and variance. More... | |
| type | stats_t |
| Structure for online computation of mean and variance. More... | |
Functions/Subroutines | |
| subroutine | stats_clear (stats) |
| Clear data statistics collected so far. More... | |
| subroutine | stats_1d_clear (stats) |
| Clear data statistics collected so far. More... | |
| subroutine | stats_2d_clear (stats) |
| Clear data statistics collected so far. More... | |
| subroutine | stats_add (stats, data) |
Add a new data value to a stats_t structure. More... | |
| subroutine | stats_1d_add (stats, data) |
Add all new data values to a stats_1d_t structure. More... | |
| subroutine | stats_1d_add_entry (stats, data, i) |
Add a new single data value to a stats_1d_t structure. More... | |
| subroutine | stats_2d_add (stats, data) |
Add all new data values to a stats_2d_t structure. More... | |
| subroutine | stats_2d_add_row (stats, data, i) |
Add a row of new data values to a stats_2d_t structure. More... | |
| subroutine | stats_2d_add_col (stats, data, j) |
Add a column of new data values to a stats_2d_t structure. More... | |
| subroutine | stats_2d_add_entry (stats, data, i, j) |
Add a single new data value to a stats_2d_t structure. More... | |
| real(kind=dp) function | stats_conf_95_offset (stats) |
| Compute the 95% confidence interval offset from the mean. More... | |
| real(kind=dp) function, dimension(size(stats%n)) | stats_1d_conf_95_offset (stats) |
| Compute the 95% confidence interval offset from the mean. More... | |
| real(kind=dp) function, dimension(size(stats%n, 1), size(stats%n, 2)) | stats_2d_conf_95_offset (stats) |
| Compute the 95% confidence interval offset from the mean. More... | |
| subroutine | update_mean_var (mean, var, data, n) |
| Compute a running average and variance. More... | |
| real(kind=dp) function | student_t_95_coeff (n_sample) |
| Return a fairly tight upper-bound on the Student's t coefficient for the 95% confidence interval. More... | |
| real(kind=dp) function | conf_95_offset (var, n_sample) |
| 95% confidence interval offset from mean. More... | |
| subroutine | stats_output_netcdf (stats, ncid, name, unit) |
| Write statistics (mean and 95% conf. int.) to a NetCDF file. More... | |
| subroutine | stats_1d_output_netcdf (stats, ncid, name, dim_name, unit) |
| Write statistics (mean and 95% conf. int.) to a NetCDF file. More... | |
| subroutine | stats_2d_output_netcdf (stats, ncid, name, dim_name_1, dim_name_2, unit) |
| Write statistics (mean and 95% conf. int.) to a NetCDF file. More... | |
| subroutine | stats_1d_output_text (stats, filename, dim) |
| Write statistics (mean and 95% conf. int.) to a text file. More... | |
Detailed Description
The stats_t type and associated subroutines.
Function/Subroutine Documentation
◆ conf_95_offset()
| real(kind=dp) function pmc_stats::conf_95_offset | ( | real(kind=dp), intent(in) | var, |
| integer, intent(in) | n_sample | ||
| ) |
95% confidence interval offset from mean.
If mean and var are the sample mean and sample variance of n data values, then
offset = conf_95_offset(var, n)
means that the 95% confidence interval for the mean is [mean - offset, mean + offset].
If n_sample is one or less then zero is returned.
- Parameters
-
[in] var Sample variance of data. [in] n_sample Number of samples.
- Returns
- Return offset from mean for the 95% confidence interval.
◆ stats_1d_add()
| subroutine pmc_stats::stats_1d_add | ( | type(stats_1d_t), intent(inout) | stats, |
| real(kind=dp), dimension(:), intent(in) | data | ||
| ) |
Add all new data values to a stats_1d_t structure.
- Parameters
-
[in,out] stats Statistics structure to add to. [in] data Data values to add.
◆ stats_1d_add_entry()
| subroutine pmc_stats::stats_1d_add_entry | ( | type(stats_1d_t), intent(inout) | stats, |
| real(kind=dp), intent(in) | data, | ||
| integer, intent(in) | i | ||
| ) |
Add a new single data value to a stats_1d_t structure.
- Parameters
-
[in,out] stats Statistics structure to add to. [in] data Data value to add. [in] i Index of data value to add.
◆ stats_1d_clear()
| subroutine pmc_stats::stats_1d_clear | ( | type(stats_1d_t), intent(inout) | stats | ) |
◆ stats_1d_conf_95_offset()
| real(kind=dp) function, dimension(size(stats%n)) pmc_stats::stats_1d_conf_95_offset | ( | type(stats_1d_t), intent(in) | stats | ) |
◆ stats_1d_output_netcdf()
| subroutine pmc_stats::stats_1d_output_netcdf | ( | type(stats_1d_t), intent(in) | stats, |
| integer, intent(in) | ncid, | ||
| character(len=*), intent(in) | name, | ||
| character(len=*), intent(in), optional | dim_name, | ||
| character(len=*), intent(in), optional | unit | ||
| ) |
Write statistics (mean and 95% conf. int.) to a NetCDF file.
- Parameters
-
[in] stats Statistics structure to write. [in] ncid NetCDF file ID, in data mode. [in] name Variable name in NetCDF file. [in] dim_name NetCDF dimension name for the variable. [in] unit Unit of variable.
◆ stats_1d_output_text()
| subroutine pmc_stats::stats_1d_output_text | ( | type(stats_1d_t), intent(in) | stats, |
| character(len=*), intent(in) | filename, | ||
| real(kind=dp), dimension(:), intent(in) | dim | ||
| ) |
Write statistics (mean and 95% conf. int.) to a text file.
The format has three columns: dim mean ci_offset where dim is the optional dimension argument, mean is the mean value and ci_offset is the 95% confidence interval offset, so the 95% CI is mean - ci_offset, mean + ci_offset.
- Parameters
-
[in] stats Statistics structure to write. [in] filename Filename to write to. [in] dim Dimension array (independent variable).
◆ stats_2d_add()
| subroutine pmc_stats::stats_2d_add | ( | type(stats_2d_t), intent(inout) | stats, |
| real(kind=dp), dimension(:, :), intent(in) | data | ||
| ) |
Add all new data values to a stats_2d_t structure.
- Parameters
-
[in,out] stats Statistics structure to add to. [in] data Data values to add.
◆ stats_2d_add_col()
| subroutine pmc_stats::stats_2d_add_col | ( | type(stats_2d_t), intent(inout) | stats, |
| real(kind=dp), dimension(:), intent(in) | data, | ||
| integer, intent(in) | j | ||
| ) |
Add a column of new data values to a stats_2d_t structure.
- Parameters
-
[in,out] stats Statistics structure to add to. [in] data Data values to add. [in] j Column of data value to add.
◆ stats_2d_add_entry()
| subroutine pmc_stats::stats_2d_add_entry | ( | type(stats_2d_t), intent(inout) | stats, |
| real(kind=dp), intent(in) | data, | ||
| integer, intent(in) | i, | ||
| integer, intent(in) | j | ||
| ) |
Add a single new data value to a stats_2d_t structure.
- Parameters
-
[in,out] stats Statistics structure to add to. [in] data Data values to add. [in] i First index of data value to add. [in] j Second index of data value to add.
◆ stats_2d_add_row()
| subroutine pmc_stats::stats_2d_add_row | ( | type(stats_2d_t), intent(inout) | stats, |
| real(kind=dp), dimension(:), intent(in) | data, | ||
| integer, intent(in) | i | ||
| ) |
Add a row of new data values to a stats_2d_t structure.
- Parameters
-
[in,out] stats Statistics structure to add to. [in] data Data values to add. [in] i Row of data value to add.
◆ stats_2d_clear()
| subroutine pmc_stats::stats_2d_clear | ( | type(stats_2d_t), intent(inout) | stats | ) |
◆ stats_2d_conf_95_offset()
| real(kind=dp) function, dimension(size(stats%n, 1), size(stats%n, 2)) pmc_stats::stats_2d_conf_95_offset | ( | type(stats_2d_t), intent(in) | stats | ) |
◆ stats_2d_output_netcdf()
| subroutine pmc_stats::stats_2d_output_netcdf | ( | type(stats_2d_t), intent(in) | stats, |
| integer, intent(in) | ncid, | ||
| character(len=*), intent(in) | name, | ||
| character(len=*), intent(in), optional | dim_name_1, | ||
| character(len=*), intent(in), optional | dim_name_2, | ||
| character(len=*), intent(in), optional | unit | ||
| ) |
Write statistics (mean and 95% conf. int.) to a NetCDF file.
- Parameters
-
[in] stats Statistics structure to write. [in] ncid NetCDF file ID, in data mode. [in] name Variable name in NetCDF file. [in] dim_name_1 First NetCDF dimension name for the variable. [in] dim_name_2 Second NetCDF dimension name for the variable. [in] unit Unit of variable.
◆ stats_add()
| subroutine pmc_stats::stats_add | ( | type(stats_t), intent(inout) | stats, |
| real(kind=dp), intent(in) | data | ||
| ) |
◆ stats_clear()
| subroutine pmc_stats::stats_clear | ( | type(stats_t), intent(inout) | stats | ) |
◆ stats_conf_95_offset()
| real(kind=dp) function pmc_stats::stats_conf_95_offset | ( | type(stats_t), intent(in) | stats | ) |
◆ stats_output_netcdf()
| subroutine pmc_stats::stats_output_netcdf | ( | type(stats_t), intent(in) | stats, |
| integer, intent(in) | ncid, | ||
| character(len=*), intent(in) | name, | ||
| character(len=*), intent(in), optional | unit | ||
| ) |
◆ student_t_95_coeff()
| real(kind=dp) function pmc_stats::student_t_95_coeff | ( | integer, intent(in) | n_sample | ) |
Return a fairly tight upper-bound on the Student's t coefficient for the 95% confidence interval.
The number of degrees of freedom is one less than n_sample. If a set of  numbers has sample mean
numbers has sample mean  and sample standard deviation
and sample standard deviation  , then the 95% confidence interval for the mean is
, then the 95% confidence interval for the mean is ![$[\mu - r\sigma/\sqrt{n}, \mu + r\sigma/\sqrt{n}]$](form_199.png) , where
, where r = student_t_95_coeff(n_sample).
The method used here was written by MW on 2011-05-01, based on the following empirical observation. If  is the function we want, where
is the function we want, where  is the number of degrees-of-freedom, then set
is the number of degrees-of-freedom, then set  , where
, where  is the limiting value given by the Gaussian CDF
is the limiting value given by the Gaussian CDF  . We observe numerically that
. We observe numerically that  and
and  as
as  . Thus
. Thus  is well-approximated by
is well-approximated by  for some
for some 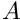 . Furthermore, if
. Furthermore, if  , then
, then  for
for  . We thus have
. We thus have  for
for  . By using a sequence of known
. By using a sequence of known  pairs we can thus construct a fairly tight upper bound.
pairs we can thus construct a fairly tight upper bound.
This implementation has an error of below 0.1% for all values of n_sample.
- Parameters
-
[in] n_sample Number of samples.
◆ update_mean_var()
| subroutine pmc_stats::update_mean_var | ( | real(kind=dp), intent(inout) | mean, |
| real(kind=dp), intent(inout) | var, | ||
| real(kind=dp), intent(in) | data, | ||
| integer, intent(in) | n | ||
| ) |
Compute a running average and variance.
Given a sequence of data x(i) for i = 1,...,n, this should be called like
do i = 1,n call update_mean_var(mean, var, x(i), i) end do
After each call the variables mean and var will be the sample mean and sample variance of the sequence elements up to i.
This computes the sample mean and sample variance using a recurrence. The initial sample mean is  and the initial sample variance is
and the initial sample variance is  for
for  , and then for
, and then for  we use the mean update
we use the mean update
![\[ m_n = m_{n-1} + \frac{x_n - m_{n-1}}{n} \]](form_175.png)
and the variance update
![\[ v_n = \frac{n - 2}{n - 1} v_{n-1} + \frac{(x_n - m_{n-1})^2}{n}. \]](form_176.png)
Then  and
and  are the sample mean and sample variance for
are the sample mean and sample variance for  for each .
for each .
The derivation of these formulas begins with the definitions for the running total
![\[ t_n = \sum_{i=1}^n x_i \]](form_181.png)
and running sum of square differences
![\[ s_n = \sum_{i=1}^n (x_i - m_n)^2. \]](form_182.png)
Then the running mean is  , the running population variance is
, the running population variance is  , and the running sample variance
, and the running sample variance  .
.
We can then compute the mean update above, and observing that
![\[ s_n = \sum_{i=1}^n x_i^2 - n m_n^2 \]](form_186.png)
we can compute the sum-of-square-dfferences update identity
![\[ s_n = s_{n-1} + \frac{n - 1}{n} (x_n - m_{n-1})^2. \]](form_187.png)
The algorithm then follows immediately. The population variance update is given by
![\[ p_n = \frac{n-1}{n} p_{n-1} + \frac{(x_n - m_n)(x_n - m_{n-1})}{n} = \frac{n-1}{n} p_{n-1} + \frac{n-1}{n^2} (x_n - m_{n-1})^2. \]](form_188.png)
This algorithm (in a form where and  are tracked) originally appeared in:
are tracked) originally appeared in:
B. P. Welford [1962] "Note on a Method for Calculating Corrected Sums of Squares and Products", Technometrics 4(3), 419-420.
Numerical tests performed by M. West on 2012-04-12 seem to indicate that there is no substantial difference between tracking versus .
The same method (tracking and ) is presented on page 232 in Section 4.2.2 of Knuth:
D. E. Knuth [1988] "The Art of Computer Programming, Volume 2: Seminumerical Algorithms", third edition, Addison Wesley Longman, ISBN 0-201-89684-2.
An analysis of the error introduced by different variance computation methods is given in:
T. F. Chan, G. H. Golub, and R. J. LeVeque [1983] "Algorithms for Computing the Sample Variance: Analysis and Recommendations", The American Statistician 37(3), 242-247.
The relative error in of Welford's method (tracking and ) is of order  , where
, where  is the machine precision and
is the machine precision and  is the condition number for the problem, which is given by
is the condition number for the problem, which is given by
![\[ \kappa = \frac{\|x\|_2}{\sqrt{s_n}} = \sqrt{1 + \frac{m_n^2}{p_n}} \approx \frac{m_n}{p_n}. \]](form_193.png)
This analysis was apparently first given in:
T. F. C. Chan and J. G. Lewis [1978] "Rounding error analysis of algorithms for computing means and standard deviations", Technical Report No. 284, The Johns Hopkins University, Department of Mathematical Sciences.
- Parameters
-
[in,out] mean Mean value to update (on entry  , on exit ).
, on exit ). [in,out] var Variance value to update (on entry  , on exit ).
, on exit ). [in] data Data value  .
. [in] n Number of this data value.